
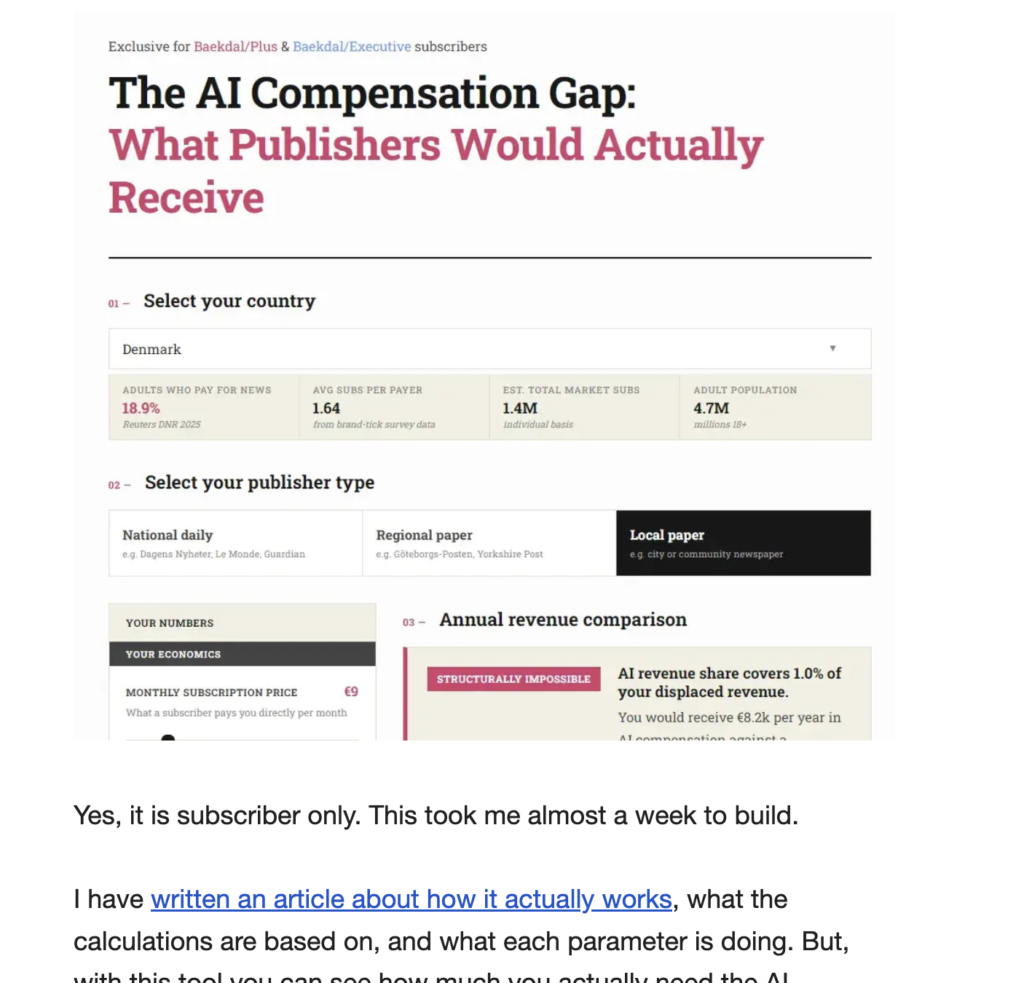
What Is an Article Actually Worth?
In the current fight between publishers and AI companies, the article is treated as a sacred atom of value. Each piece is presented as a unit of intellectual property that platforms are allegedly stealing, one story at a time. But if you look at how digital publishing has actually worked, almost nobody has ever priced journalism that way. The system has always valued the bundle, not the atom.
An article does not live alone. It sits inside a catalog, under a brand, in a feed and a section and a subscription tier, surrounded by other pieces readers may or may not see. It participates in a larger machine of homepages, newsletters, push alerts, social feeds, and search rankings. What people pay for, when they pay at all, is access to that system: the accumulated archive, the editorial filter, the general promise that “this is the kind of place that covers things you care about.” The individual article is just one node in that network.
This isn’t an argument against paying for journalism; it’s an argument against pretending that every article has the same value, or that the system ever treated them that way.
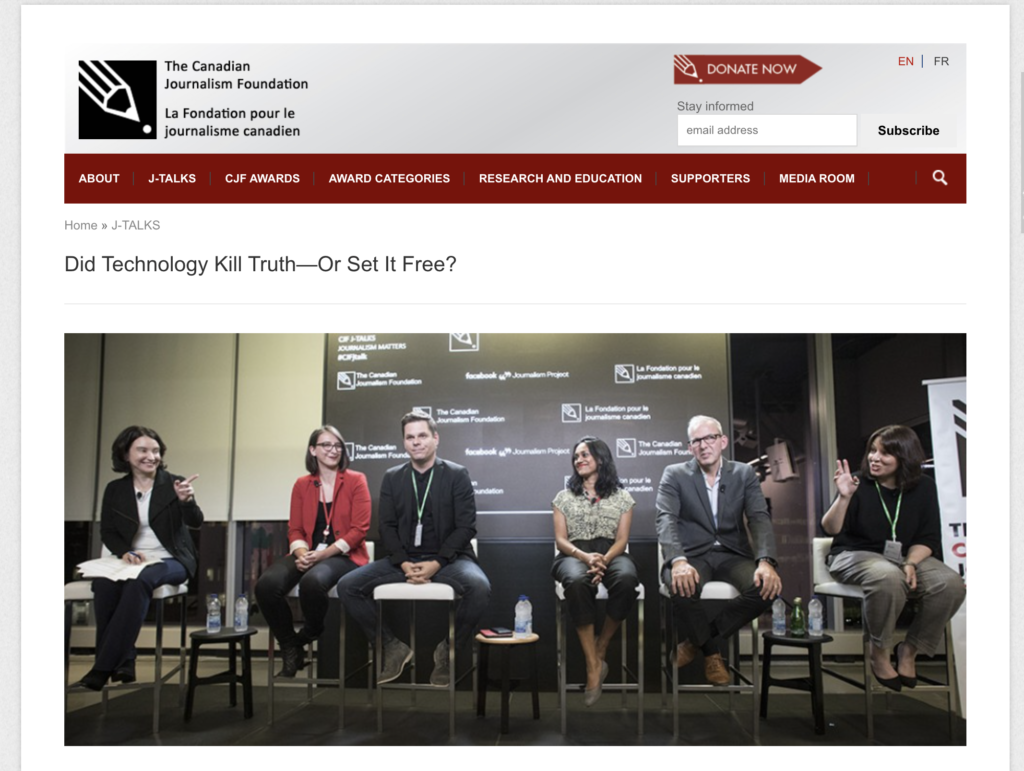
Almost a decade ago, the industry already knew how skewed this network was. At a Toronto J‑Talk panel on “Did technology kill truth—or set it free?”, held at Facebook’s office, the official topic was truth and journalism. In practice, what everyone wanted to talk about was Chartbeat. On those real‑time dashboards, editors could see a quiet horror: most pieces were getting almost no attention at all. Many articles didn’t get a single click, not even from the reporter’s mother. Chartbeat’s own analysis emphasized that attention was radically concentrated and that clicks were a crude comfort metric masking how little most stories were actually read. Editors could see the skew in real time and still kept feeding the machine, adding more low‑attention pieces to already swollen catalogs.
Traffic data from news and content sites has been telling that same story ever since. A small minority of pages drive the vast majority of visits, while most articles barely register. Analyses of audience behavior show that a handful of “hits” attract disproportionate attention, while a long tail of ordinary coverage drifts along with negligible readership. Economically, an archive behaves less like a neatly used library and more like a lottery: a few winning tickets subsidize hundreds or thousands of duds.
That lottery structure is now colliding with the “zero‑click” reality. Over the last few years, search behavior has shifted from “click to read” toward “read the answer where you are.” Zero‑click queries, where the user never leaves the search or AI interface, have become the dominant pattern in many categories, and click‑through rates fall sharply when AI overviews appear. At the same time, global data shows publisher traffic from Google dropping by around a third in 2025 alone, with some segments and smaller outlets experiencing even steeper declines as AI summaries and rich results displace traditional links. The thin layer of referral value that once justified the long tail of weak articles has eroded.
This also changes the cost side of the equation. Large‑scale crawling and AI‑related bot traffic now put load on servers without sending back human readers, pushing publishers into higher infrastructure costs and mitigation efforts with “no meaningful value exchange” attached. A long tail of low‑traffic articles still must be stored, indexed, defended, and served, but their main role in practice is increasingly to feed external systems that do not return attention to the original publisher. For many of those pieces, their net economic contribution is negative: they consume reporting time, editorial resources, legal oversight, and hosting, while generating almost nothing on their own.
Meanwhile, look at how AI companies actually pay for content when they do. The high‑profile deals we know about are not per‑article micro‑payments; they are large, multi‑year catalog licenses and brand partnerships. Observers tracking the first wave of agreements have estimated typical news and magazine deals in the eight‑figure range, and total commitments across publishers in the low billions, structured as lump sums in exchange for broad rights. These contracts buy breadth of access, legal clarity, risk reduction, and association with recognized brands, not a line‑item valuation of each individual story. In other words, AI companies are now doing what advertisers, cable operators, and newsstands did before them: paying for a bundle.
So what, then, is an article “worth”? If you strip away the rhetoric and look at the system, the answer is uncomfortable. A small number of stories are extraordinarily valuable in context: they attract readers, drive subscriptions, and anchor a brand’s reputation. A somewhat larger band of work is modestly useful, filling gaps, serving regulars, and supporting beats. And beyond that lies a vast ghost archive quietly losing money each year, an inventory of weak, barely read articles that has become parasitic on the system: soaking up time, money, and now bot traffic, while contributing almost nothing measurable. The worth of any single article is not a stable property you can meter and invoice; it is an emergent property of how that article interacts with a larger ecosystem of discovery, monetization, and reputation.
There is also a more awkward question for both publishers and AI companies: how valuable is the bloat itself as “knowledge”? Not all long‑tail content is junk; in machine‑learning terms, rare cases and edge examples can improve a model’s understanding of the world. But a great deal of what sits in back catalogues, duplicative rewrites, low‑depth takes, orphaned blog posts, looks less like unique signal and more like statistical noise. It fills a database and fattens a training set without necessarily telling either humans or machines anything they could not have learned from a much smaller, better‑curated subset.
This is not a problem that arrived with AI. Before large language models, there was already an entire ecosystem of aggregators and databases that bought or licensed backfiles and then discovered that demand for the deep archive was thin. Usage studies of big citation indexes and abstracting services showed heavy concentration on a small fraction of content, while many specialized databases ended up merging, being sold, or shutting down. Even in scholarly publishing, where citations are a primary currency, analyses of major indexes such as Scopus and Web of Science have repeatedly found that large shares of articles, often over half in arts and humanities, remain uncited several years after publication. Google Scholar makes that visible in another way: every researcher has a long tail of work that exists in the system but is effectively invisible to the conversation.
Seen from that angle, AI is not uniquely disrespectful of individual articles. It is simply the latest technology to confront the same structural fact: in large collections of human work, most units of content will have very little direct, traceable impact. The long tail still matters for completeness, for certain edge cases, and for preserving access to the “original distribution” of human output that future systems may need. But that does not mean every item in the tail is meaningfully valuable on its own, or that any funding model, analog, digital, or AI‑driven, can honestly pretend otherwise.
This pattern is not new: print newspapers also bulked out their bundles with wire copy, recipes, advice columns, and comics so the product looked thick enough to justify the ads inside. The digital archive is just that impulse made searchable.
The tension in today’s arguments comes from trying to retrofit a per‑article moral claim onto an infrastructure that never really worked that way. Digital publishing was financed by bundles, cross‑subsidies, and the surplus generated by a few winners, all obscured under aggregate metrics like “monthly uniques” and “pageviews.” Now, as those clicks disappear into AI answer boxes and other zero‑click experiences, publishers are asking to be paid as if every article were a high‑value asset, even though their own history and data show that most pieces have always been closer to structural filler than to individually valuable goods. The real question is not what a single article deserves in the abstract, but how to fund a public‑facing information system once the old mechanisms that hid the true distribution of value have broken down.
Tags: AI, Artificial Intelligence, Canadian Journalism Foundation, Chartbeat, Facebook, J-Talk, Journalism, Thomas Baekdal